

File 01: Purpose of AI Critique
Takaya Arita
「AI Critique」はアート作品をとりあげ,大規模言語モデル(LLM)が生成したそれに対する批評を掲載するオンライン・テクニカル・レポートである.本稿では,創刊の趣旨について述べる.
AI Critique is an online technical report series that features artworks alongside critiques generated by large language models (LLMs). The present article outlines the purpose of its publication.
1.生成AIのパラドクス
人工知能(AI),特に大規模言語モデル(LLM)の発展は著しく,単なるツールとしての存在を超えて,人類のアイデンティティを揺るがすような存在になりつつある.LLMの影響はもちろんポジティブ・ネガティブの両面あるが,特にアートに関して言えば,(本稿では一つの側面にだけ言及するが)いくつかの次元での影響の相互作用の結果として,極めてポジティブであると考えている.
AIとアートというと,誰もがまず考えるのがLLMなどの生成AIによるアート作品の生成ではないだろうか.実際,テキストやイメージ等の生成能力は想像を超える発展を日々遂げており,すでに,人間の生成したものと区別がつかない(中には超えているといっても語弊でない)ようなジャンルは少なくない.写真の発明が絵画の世界に変革をもたらしたように,あるいはそれ以上の大きな変革をアートの広い分野に与えていくであろう.
ただ,ここで考えてみたいのは,とても素晴らしい文章を,絵画を,動画を生成できるからといって,本当に何かを理解して表現しているのかということである.ほぼすべての人はここに人間との決定的な差を認めるだろう.これを「生成AIのパラドクス」(Fig. 1)と呼ぶ.「人間はきちんと理解し,それに基づいて生成するが,生成AIは理解なしに生成できてしまうのだ」ということである.
私はこれに対して,「そんなことはない!」と異を唱える.そして,理解とは何か,人間とは何かということから始まる議論には入らずに,理解しているとしか考えられないようなものを無言で(?)ど〜んと見せて納得させるという戦略をここでは選ぶ.要するに,アート作品を生成させるのではなく,アート作品に対する批評を書かせ,その批評の深さを示していくことによって,このパラドクスに対して異議を唱えていこうと考える.
1. The Paradox of Generative AI
The development of artificial intelligence (AI) has been a remarkable phenomenon in recent years, particularly in the domain of Large Language Models (LLMs). These entities are evolving beyond the status of mere tools and are exhibiting the potential to challenge humanity's very identity. While the impact of LLMs undoubtedly encompasses both positive and negative aspects, it is the contention of this paper that, specifically regarding art (though this paper addresses only one facet), the resultant interplay of influences across several dimensions is profoundly positive.
In the realm of AI and art, the predominant perspective is oriented towards the generation of artworks by generative AI, such as LLMs. The remarkable capacity of these models to produce text, images, and other forms of expression is advancing at an unprecedented rate, surpassing the bounds of imagination. In numerous genres, the output of these generative AI models is now indistinguishable from human creation, and in some cases, it can be argued that the quality of their output surpasses that of humans. The profound impact of generative AI on the artistic landscape is comparable to the revolutionary transformation brought about by the invention of photography in the world of painting. It can be posited that generative AI will catalyse an even more significant metamorphosis across the broader spectrum of artistic disciplines.
However, the present discussion pertains to the consideration of whether the capacity to produce prose, paintings, or videos of remarkable quality is indicative of genuine comprehension and expression. It is a commonly acknowledged distinction from humans in this regard. This phenomenon may be referred to as the ‘Generative AI Paradox’ (Fig. 1). The crux of the paradox lies in the fact that ‘humans generate based on proper understanding, but generative AI can generate without understanding.’
The present author takes issue with this statement, declaring, ‘That's not the case!’ Rather than entering into a debate starting with questions like ‘What is understanding?’ or ‘What defines humanity?’, a different strategy is proposed here. This strategy is to silently present something so compelling that it can only be interpreted as understanding, thereby compelling acceptance. In essence, rather than generating artworks, it is proposed that this paradox be challenged by having the AI write critiques of artworks and demonstrating the depth of those critiques.
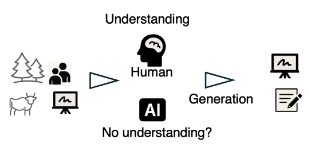
Fig. 1 Generative AI Paradox.
2.アート作品批評の生成手法
どういう理論に基づいてアート作品批評を生成するか? これを考える際の重要な論点として,作品の評価にまで踏み込むか,それとも解釈にとどめるかどうかという点がある.これに関しては,評価を避けて解釈に重きを置く立場が20世紀後半の主流であった.一方,ノエル・キャロル[Carroll, 2009]は,評価,つまり価値判断こそが批評家の最大の仕事であるとした.さらに,作品の価値として,「受容価値」(reception value) ,つまり,作品が鑑賞者に与える感情,解釈,経験に基づく価値ではなく,「成功価値」(success value)の重要性を強調した.これは,作家の意図やコンセプトに照らして,その作品がどれだけ達成しているかということに焦点をあわせる評価基準である.
我々は,キャロルの提唱するような理由付けられた判断はLLMが得意とするところであり,極めて相性がよいものと考え,アート生成における理論的な枠組みとして採用して,生成系を構成した.具体的な枠組みとしては,まず,批評の構成要素を「記述」,「分類」,「文脈づけ」,「解明」,「解釈」,「分析」 ,「価値づけ」とした上で,批評を批評たらしめる必要不可欠な重要な要素を「価値づけ」とした.そして,それ以外の要素は「価値づけ」を導くための基盤と位置づけ,全部が揃う必要はないものとする.
さらに我々は,多面的な視点をもつ批評を生成できるようにするために,それぞれの構成要素において採用しうる理論をLLMに対して知識として網羅的に提示した.次の15個の批評理論である:構造主義批評,物語論批評,受容理論批評,脱構築批評,精神分析批評,テーマ批評,フェミニズム批評,ジェンダー批評,生成論批評,マルクス主義批評,文化唯物論/新歴史主義批評,ソシオクリティック,カルチュラル・スタディーズ,システム理論批評,ポストコロニアル批評/トランスナショナリズム [小倉,2023].
このように,LLMに対して批評の大きな枠組み(構成要素)を示した上で,それぞれの構成要素で適用できる批評理論を示した.さらに,批評の文体を学ばせるために,アート作品に対する短い記述を集めたデータセットも入力した.全体の構成をFig. 2に示す.
このようにして,LLMに対して作品のイメージを入力すると7個の構成要素からなる批評文ができるが,引き続いて,それを数段落からなるように圧縮させることにより,批評全体の一貫性,文体の自然さや可読性を向上させる.最後のステップとして,作品の本質を最小限で表す1文批評を生成させる.このような段階的なプロセスは,Chain-of-Thought (CoT)と呼ばれるプロンプト生成の手法である.
2. Methodology for Generating Artwork Critiques
A fundamental question to consider in this regard is the theoretical basis that should underpin the generation of art criticism. A crucial point to consider here is whether to venture into the domain of evaluating the work itself, or to confine oneself to interpretation. Regarding this, the mainstream approach in the latter half of the 20th century was to avoid evaluation and to place emphasis on interpretation. In contrast, Noel Carroll [Carroll, 2009] proposed that the paramount task of the critic is evaluation, that is to say, value judgement. Moreover, he placed considerable emphasis on success value as opposed to reception value. By this, he means the value derived from the emotions, interpretations, and experiences that the work imparts to the viewer. This evaluative criterion focuses on the extent to which a work achieves its objectives in light of the author's intent or concept.
We adopted Carroll's proposed framework of reasoned judgements as the theoretical basis for our art generation system, considering it to be exceptionally well-suited to the strengths of Large Language Models (LLMs). In the initial phase of our inquiry, we embarked on the task of delineating the components of criticism. Through a rigorous analytical process, we established the following components: description, classification, contextualisation, elucidation, interpretation, analysis, and evaluation. Subsequent to this preliminary phase, we proceeded to identify “evaluation” as the indispensable, crucial element that constitutes criticism. The remaining components were thus positioned as foundations to derive “evaluation”, meaning their presence is not strictly necessary.
Furthermore, To enable the generation of multifaceted criticism, we comprehensively presented the LLM with knowledge encompassing theories applicable to each constituent element. These are the following 15 critical theories: Structuralist Criticism, Narratology Criticism, Reception Theory Criticism, Deconstructionist Criticism, Psychoanalytic Criticism, Thematic Criticism, Feminist Criticism, Gender Criticism, Genetic Criticism, Marxist Criticism, Cultural Materialist Criticism/New Historicist Criticism, Socio-criticism, Cultural Studies, Systems Theory Criticism, and Postcolonial Criticism/Transnationalism [Ogura, 2023].
In this way, we presented the broad framework (constituent elements) of criticism to the LLM, while also indicating the critical theories applicable to each constituent element. Furthermore, to teach the LLM the style of criticism, we also input a dataset containing short descriptions of artworks. The overall structure is shown in Fig. 2.
By inputting an image of the work to the LLM in this manner, a critique consisting of seven components is generated. Subsequently, compressing this into several paragraphs enhances the overall consistency, stylistic naturalness, and readability of the critique. As a final step, a one-sentence critique that minimally captures the essence of the work is generated. This stepwise process is a prompt generation technique called Chain-of-Thought (CoT).
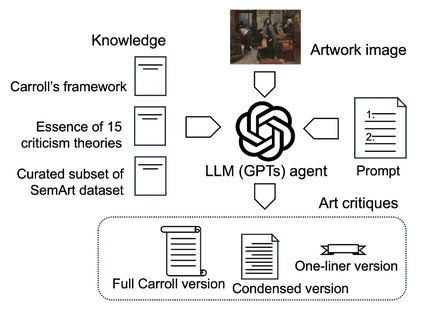
Fig. 2 Cinfiguration of Composer.
3.チューリングテストによる批評の評価
このようにして生成されたAI批評が人間の専門家による批評と比較してどこまで達しているかを調べるためにチューリングテストを行った(Fig. 3).アート作品に対する専門家による批評とLLMが生成した批評の両者を被験者に見せて,どちらが人間作(あるいはLLM作)かを判断させ,その正解率で評価するというものである.
実は,アート作品に対するAIと人間による批評の選択・生成(Fig. 4)にはかなりの検討が必要であった.まず,作品の選択である.ウェブ等にその作品に関する批評やコメント等が少なからず掲載されているならば,すでにそのテキストをLLMが学習している可能性がある.本格的なアート作品批評に関する研究は(私たちの知る限り)今のところ存在しないが,イメージからキャプション程度を生成するような研究ではWikipedia等を学習させる方針を取っている.我々は人間の書いたものを寄せ集めるようなものではなく,未知の作品に対しても変わらずに深く理解して価値判断し,高いレベルの批評を書けるかということを評価したいので,逆のスタンスを取ることにした.
この方針から,まず,対象作品の選定においては,LLMに対してイメージを入力して作品名や作者名を問うて正しく回答するものは,すでに学習済みとして除外した.そのようにして対象作品を決めた上で,先述の生成過程における第二段階の批評,つまりキャロルの枠組みに忠実な詳細な批評を洗練して3段落としたバージョンを採用した.
一方,人間の適切な批評を探索するのは簡単ではなかった.人工知能研究で用いられているデータセットは基本的にキャプションの類のもので,美学的に深いと言えるような批評は私の知る限り皆無であるからだ.結局,美術史研究の非営利団体Smarthistory(https://smarthistory.org/)から多くを選定した.その際,作品だけからは得られないような事実に基づいている記述が含まれる場合には,即座に人間の執筆とわかってしまうので除外した.
さて,肝心の結果はどうだったか.60人の被験者によるもっとも基本的な結果をFig. 5に示す.このグラフは5つの作品に対して被験者が正しく人間作とLLM作を判別できた割合を示したものである.前提として,批評も読まずにデタラメに回答しても半分,つまり0.5になるということである.さて,このグラフを一見してわかることは,ほぼ0.5,より詳しく見ると0.5から0.6の間ぐらいに分布しているということである.つまり,両者の区別はほぼできないと表現していいだろう.
一つ気がつくのは4番目の問題は正解率が0.3と極めて小さいことである.私のほんの小さな悪意というかイタズラ心が表出して引っ掛け問題を入れたためであって,案の定の結果と言ってよいかもしれない.この出題は,皮肉・風刺の類の表現をLLM生成の一行批評(この作品に対してだけこのタイプを採用した)とペアにしたものである.そういう皮肉の気持ちが理解できないと,どう考えてもLLMの批評のほうがまともなので,つい間違えてしまうのである.
ところで,チューリングテストはそもそも会話の相手としてAIがどこまで人間になりきれるかということを試すものであった.そのため,従来のチューリングテストをパスするための必要十分条件はいかに人間らしく振る舞うかということであった.典型的にはわざとミスタイプをまぜるなどの言ってみれば姑息なテクニックも重要であった.
この被験者実験では上記のような判別課題の回答だけでなく,判断理由の自由記述も求めた.その分析の結果,批評の文章スタイルを理由とした人は少なく,正確な内容,詳細な背景知識,深い解釈,説得力などが上位の理由であることがわかった.つまり,美学的な観点を含む,表面的な表現スタイルのレベルにとどまらないレベルにおいて,人間の専門家に匹敵しうるような批評をLLMが生成しうることを示すことができたと言える.つまり,冒頭に記した生成AIのパラドクスが実は成立していないのではないかという方向性をサポートする結果である.
ところで,私はさらなるLLMの発展を待たなくてもすでにLLMは人間の書く批評を超えるものを書く能力を潜在的には持っているのではないかと信じている.それを引き出そうとするアプローチにおいては,どのような批評を望むかという人間側の美学的な見識,スタンスこそが問われることになると思う.そして,その場合には,人間作の批評と区別できないかという問題設定自体が無意味になるであろう.
3. Evaluating Criticism via the Turing Test
We conducted a Turing test (Fig. 3) to assess how well the AI-generated criticism measured up against critiques by human experts. Subjects were shown both expert criticism and LLM-generated criticism of artworks and asked to determine which was human-made (or LLM-made), with evaluation based on their accuracy rate.
The selection and generation of both AI and human critiques of artworks (Fig. 4) necessitated considerable deliberation. The initial step entailed the selection of artworks, for which the LLM would have learned the text if a significant amount of criticism or commentary on a work already existed online. Despite the absence of any dedicated research on comprehensive art criticism (as far as we are aware), studies that generate image captions generally employ a strategy of intensive training on knowledge bases such as Wikipedia. The objective of the present study was to evaluate whether the model could consistently understand, value and produce high-level criticism for unknown works, rather than merely aggregating human-written material. In order to address this objective, the opposite approach was adopted.
With this policy, works were excluded from consideration if an LLM correctly identified the title or artist when presented with an image. Once the target works had been determined, a refined, three-paragraph version of the second-stage critique from the aforementioned generation process was adopted – specifically, a detailed critique faithful to Carroll's framework.
Finding appropriate human critiques, however, proved to be a challenging endeavour. Datasets employed in AI research are fundamentally of the caption variety; to the best of my knowledge, none contain criticism of sufficient aesthetic depth. Consequently, selections were made primarily from the non-profit art history organisation Smarthistory (https://smarthistory.org/). In undertaking this endeavour, we excluded any descriptions containing facts that could not be derived exclusively from the artwork itself, as such elements would immediately reveal the involvement of a human author.
What were the crucial results? The most fundamental findings from 60 subjects are shown in Fig. 5. The graph illustrates the percentage of times subjects accurately differentiated human-made descriptions from those generated by LLM for five artworks. As a baseline, responding randomly without reading the critiques would result in a half chance, or 0.5. At first glance, the graph shows a distribution close to 0.5, and upon closer inspection, it ranges between 0.5 and 0.6. In other words, it is reasonable to conclude that the distinction between the two was virtually impossible to make.
It is interesting to note the extremely low correct answer rate of 0.3 for the fourth problem. This can be attributed to the inclusion of a trick question, which was included by the author as a result of a slight sense of mischievousness. This study employed a unique pairing of LLM-generated one-line critiques, utilizing this format exclusively for this work, with expressions of irony or satire. The failure to recognize the ironic intent inherent in these expressions can lead to misinterpretations, rendering the LLM's critique seemingly more reasonable and, consequently, resulting in errors.
The Turing Test was originally conceived as a means of assessing the extent to which an AI could convincingly emulate a human conversational partner. Consequently, the necessary and sufficient condition for passing the conventional Turing Test was the degree of human-like behaviour exhibited by the AI. Typically, even somewhat underhanded techniques, such as deliberately introducing typos, were considered significant.
The analysis demonstrated that a limited number of subjects cited the style of the critical writing as a reason; instead, the predominant reasons were accurate content, detailed background knowledge, profound interpretation, and persuasiveness. This finding indicates that LLMs are capable of generating criticism that matches the level of human experts, surpassing the confines of mere surface expression style and encompassing aesthetic perspectives. Consequently, these results offer empirical support for the position that the previously mentioned paradox of generative AI may not hold true.
It is noteworthy that despite the absence of augmented LLM development, LLMs are posited to inherently possess the capacity to generate criticism that surpasses that produced by human agents. In methodologies aimed at elucidating this potential, the crux lies in the human element's aesthetic discernment and the articulation of the desired nature of criticism. Consequently, the very delineation of the problem, namely the distinction between LLM-generated criticism and that authored by humans, becomes moot.
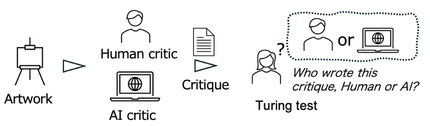
Fig. 3 Turing Test of Art Critiques by LLM.
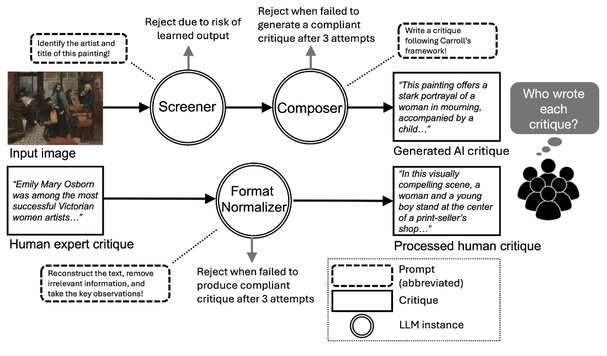
Fig. 4 Workflow for Turing test data peparation.
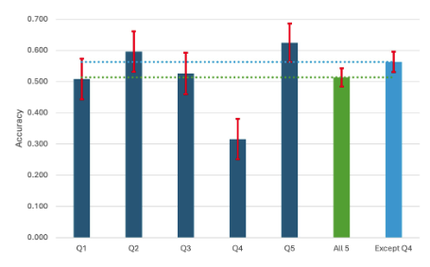
Fig. 5 Accuracy in identifying human crtiques.
4.運営方針とAI批評に基づくアート・エコロジー
本レポートでは2で概要を示した生成系が出力した批評を掲載していく.出力が英語の場合は日本語,日本語の場合は英語によるものを生成させる.原則として,出力をそのまま掲載するが,出力の中にプロンプトの指示に対応した注釈的な記述がカッコ付で含まれる場合には,それは除去する.生成系に対しては,作品イメージ以外に,作品名,作家名,また,作品によっては最小限のコメントを入力する場合もある.いずれにせよ,その情報を各レポートに明示する.なお,作品イメージに関しては縮小したものを掲載する.
以降ではいくつかの検討すべき事項について述べる。まず,詳細版批評はノエル・キャロル提唱の批評の構成要素7つ全部について生成させており,さらに,15の批評理論に基づいて否応なしに記述させている.これにより,視点の多様性を最大限に広げることを狙っているので,やや強引と思われる部分も含むだろう.しかし,次のステップで出力する洗練版では,一貫性をもたせるように詳細版を洗練・圧縮するように指示しているので,そのような部分も緩和されるはずである.実際,チューリングテストをパスした5つの課題のうち4つはこのバージョンを使用している(残りのひとつが1文批評).
また言うまでもなく,LLMでは避けて通れない次の問題が存在する.つまり,LLMにありがちな「ハルシネーション」と呼ばれるミスを(自信をもって)犯しがちであるということである.これらの問題を含む批評は,特に作家や作品の価値の低下につながるようなものである場合には,責任の所在という問題につながる可能性がある.このことは,AIの応用における本質的な倫理の問題につながる.AIの動作の結果に関して,誰がどのように責任を取るのかという問題である.
ギャラボ東京では,リアル・オンラインの両面からの新たなアプローチを採用するために,この問題に関しても創造的に解消することを狙う.それは,「AI批評に基づくアート・エコロジー(AI-Centered Ecology of Artistic Feedback)」である.これは,AIエージェントによる批評生成を基盤として,作家,鑑賞者,AIエージェント,AI設計者が作品・批評・コメントを媒介にして相互作用を繰り返すことで,作品の芸術的な意味・価値が絶えず更新されていくエコロジカルな創造環境である.このアプローチはニコラ・ブリオーの「関係性の美学」やクレア・ビショップ の「敵対性の美学」をAI時代における新たな発展として位置付けることができる.
付記)
なお,本記事で紹介したLLMによるアート作品批評の生成と60名による被験者実験(チューリングテスト)やアート批評に関わる「心の理論」課題(Fig. 6)の提案とその41個のLLMを用いた評価の詳細については,2025年に2つの論文で発表している(文献 [1][2], Fig. 7)ので,興味のある方はお読みください.
4. Operational Policy and AI-Centered Ecology of Artistic Feedback
This report will disseminate the critiques that have been generated by the generative system delineated in Sec. 2. In instances where the output is in English, the equivalent in Japanese will be generated; conversely, where the output is in Japanese, the equivalent in English will be generated. As a general rule, the output will be published in its original form. However, if the output contains explanatory notes in brackets that respond to prompt instructions, these will be removed.
Hereafter, several points worthy of consideration will be addressed. Firstly, the detailed critique generates responses covering all seven components of criticism proposed by Noel Carroll, and furthermore, it is compelled to describe based on 15 critical theories. This aims to maximise the diversity of perspectives, and consequently, it may include elements that appear somewhat forced. Nevertheless, in the ensuing phase, the refined version is directed to refine and compress the detailed version to ensure consistency, thereby mitigating such aspects. Indeed, four of the five tasks that passed the Turing test employed this version (the remaining one used a single-sentence critique).
It is important to note that the following issue, which is inevitable when working with LLMs, persists: they are prone to committing errors known as “hallucinations” (with confidence). Critiques containing such errors, particularly those potentially diminishing the value of authors or works, may raise questions of accountability. This connects to fundamental ethical issues in AI application. The issue at hand is that of establishing the entity or entities responsible for the consequences of actions undertaken by artificial intelligence (AI), and determining the manner in which this responsibility is to be assumed.
GALLABO TOKYO seeks to address this issue in a creative manner as part of an adopted approach that integrates both physical and online dimensions. This approach is designated as the ‘AI-Centred Ecology of Artistic Feedback’.
This constitutes an ecological creative environment in which the artistic meaning and value of a work are continually updated. It is based on criticism generated by artificial intelligence (AI) agents, through repeated interaction mediated by the work, criticism, and comments, involving the artist, the viewer, the AI agent, and the AI designer. This approach can be positioned as a new development in the AI era, building upon Nicolas Bourriaud's “Relational Aesthetics” and Claire Bishop's “Aesthetics of Adversity”.
Note)
For details on the generation of art criticism using LLM introduced in this article, the subject experiment (Turing test) involving 60 participants, and the proposed “theory of mind” task related to art criticism (Fig. 6) along with its evaluation using 41 LLMs, please refer to two papers published in 2025 (References [1][2], Fig. 7).
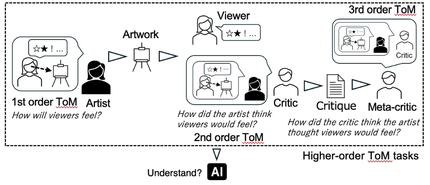
Fig. 6 Higher-order theory of mind in art criticism.

Fig. 7 Our Papers on Generating Art Critiques Using Large Language Models.
References
[1] N. Carroll, On criticism, Routledge, 2009.
[2] K. Ogura, For Those Studying Criticism Theories, Sekaishisosha, 2023 (in Japanese).
[3] T. Arita, W. Zheng, R. Suzuki, and F. Akiba, "Assessing LLMs in Art Contexts: Critique Generation and Theory of Mind Evaluation", arXiv, 2025 (doi: 10.48550/arxiv.2504.12805).
[4] W. Zheng, R. Suzuki, and T. Arita, "Artificial Intelligence as Art Critic: Design and Comparative Turing Test of Human vs. AI Critiques", Proc. of Artificail Life and Robotics (AROB), pp. 75-80, Jan. 2025.